Cloud Object Storage#
SkyPilot tasks can access data from buckets in cloud object storages such as AWS S3, Google Cloud Storage (GCS), Cloudflare R2 or IBM COS.
Buckets are made available to each task at a local path on the remote VM, so the task can access bucket objects as if they were local files.
Usage#
Object storages are specified using the file_mounts field in a SkyPilot task.
To access an existing bucket (e.g., created through cloud CLI or other tools),
specify source.
# Mount an existing S3 bucket
file_mounts:
/my_data:
source: s3://my-bucket/ # or gs://, r2://, cos://<region>/<bucket>
mode: MOUNT # Optional: either MOUNT or COPY. Defaults to MOUNT.
This will mount the contents of the bucket at s3://my-bucket/ to the remote VM at /my_data.
To create an empty bucket, specify name.
# Create an empty gcs bucket
file_mounts:
/my_data:
name: my-sky-bucket
store: gcs # Optional: either of s3, gcs, r2, ibm
SkyPilot will create an empty GCS bucket called my-sky-bucket and mount it at /my_data.
This bucket can be used to write checkpoints, logs or other outputs directly to the cloud.
Note
name must be unique to create a new bucket. If the bucket already
exists and was created by SkyPilot, SkyPilot will fetch and reuse the
bucket, so the same YAML can be reused across runs.
To create a new bucket, upload local files to this bucket and attach it to the task,
specify name and source, where source is a local path.
# Create a new S3 bucket and upload local data
file_mounts:
/my_data:
name: my-sky-bucket
source: ~/dataset # Optional: path to local data to upload to the bucket
store: s3 # Optional: either of s3, gcs, r2, ibm
mode: MOUNT # Optional: either MOUNT or COPY. Defaults to MOUNT.
SkyPilot will create a S3 bucket called my-sky-bucket and upload the
contents of ~/dataset to it. The bucket will then be mounted at /my_data
and your data will be available to the task.
If store is omitted, SkyPilot will use the same cloud provider as the task’s cloud.
Note
If the bucket already exists and was created by SkyPilot, SkyPilot will fetch
and reuse the bucket. If any files at source have changed, SkyPilot will
automatically sync the new files to the bucket at the start of the task.
You can find more detailed usage examples in storage_demo.yaml.
Storage modes#
A cloud storage can be used in either MOUNT mode or COPY mode.
MOUNT mode: The bucket is directly “mounted” to the remote VM. I.e., files are streamed when accessed by the task and all writes are replicated to the remote bucket. Any writes will also appear on other VMs mounting the same bucket. This is the default mode.
COPY mode: The files are pre-fetched and cached on the local disk. Writes only affect the local copy and are not streamed back to the bucket.
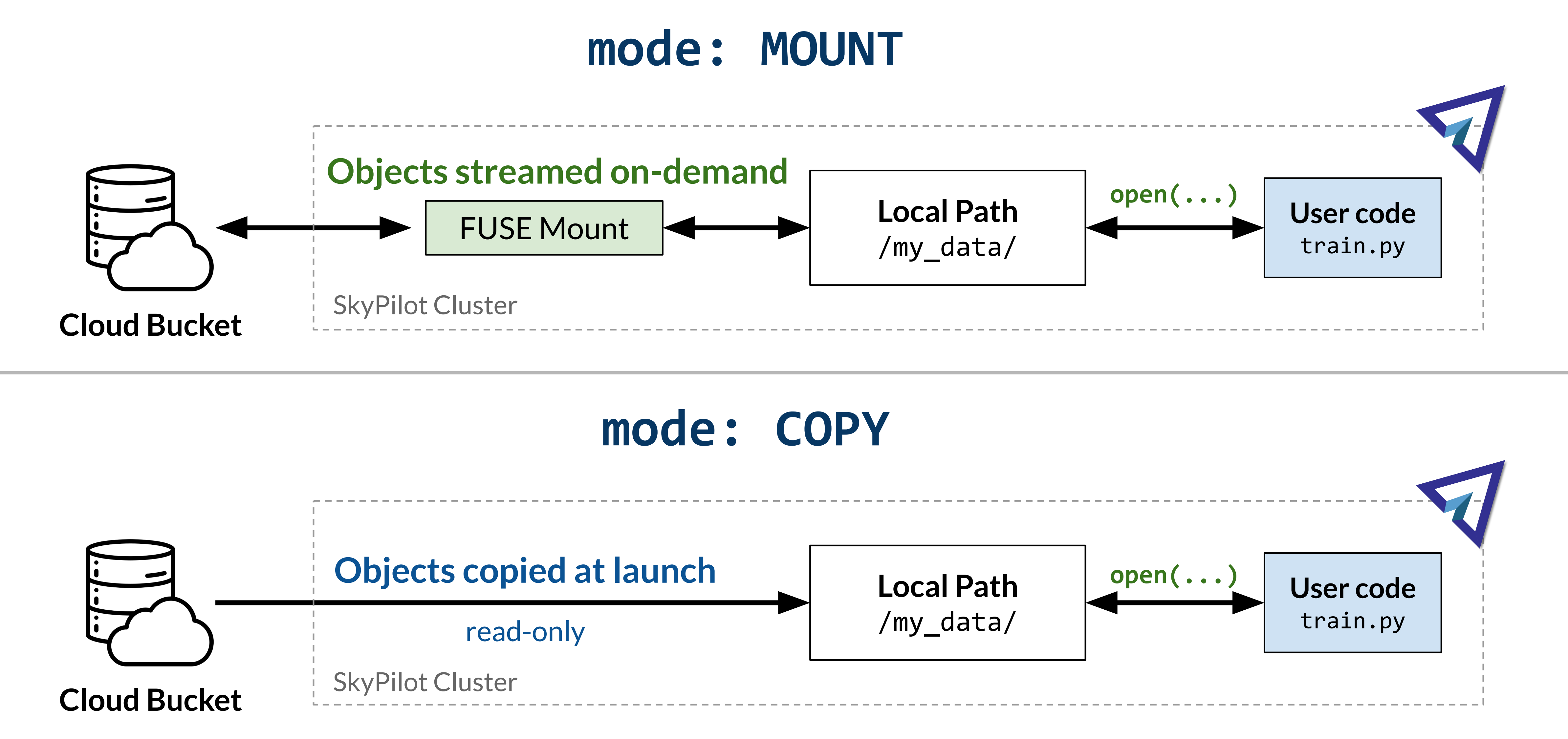
Picking a storage mode#
Choosing between MOUNT and COPY modes depends on the workload,
its performance requirements and size of the data.
|
|
|
|---|---|---|
Best for |
Writing task outputs (e.g., checkpoints, logs); reading very large data that won’t fit on disk. |
High performance read-only access to datasets that fit on disk. |
Performance |
🟡 Slow to read/write files. Fast to provision. |
✅ Fast file access. Slow at initial provisioning. |
Writing to buckets |
🟡 Most write operations [1] are supported. |
❌ Not supported. Read-only. |
Disk Size |
✅ No disk size requirements [2] . |
🟡 VM disk size must be greater than the size of the bucket. |
Note
Under the hood, MOUNT mode uses FUSE
to provide a close-to-open consistency model for attached buckets. This means calling
close() on a file will upload the entire file to the bucket.
Any subsequent reads will see the latest data.
Note
SkyPilot does not guarantee preservation of file permissions when attaching buckets. You may need to set file permissions during task execution.
Note
Symbolic links are handled differently in file_mounts depending on whether buckets are used.
For bucket mounts, symbolic links are not copied to remote.
For local file_mounts that are directly rsynced to the VM,
the symbolic links are directly copied, not their target data.
The targets must be separately mounted or else the symlinks may break.
Common patterns#
Reading datasets#
If your dataset is already in a cloud bucket, you can directly mount it to your remote VM.
# Mount an existing S3 bucket containing a dataset
file_mounts:
/my_data:
source: s3://my-dataset/
mode: MOUNT
Tip
If your dataset can fit on the VM’s disk, you can use mode: COPY to
improve the I/O performance of your task. See Storage modes for more details.
Storing task outputs#
You can directly write the outputs of your tasks to a cloud bucket by creating
a new bucket and using it in MOUNT mode.
💡 Example use case: Writing model checkpoints, logs from training runs.
# Creates an empty bucket. Any writes to /my_data will be replicated to s3://my-sky-bucket
file_mounts:
/my_data:
name: my-sky-bucket
store: s3
Your task can then write files to /my_data and they will be automatically
be uploaded to the cloud.
Avoid re-uploading data on every run#
Compared to directly using local paths in file_mounts, uploading to a bucket can be faster because it is persistent and thus requires fewer uploads from your local machine.
💡 Example use case: Uploading local dataset or files once and using it in multiple tasks.
# Creates a bucket and reuses it in multiple tasks and runs
file_mounts:
/my_data:
name: my-sky-bucket
source: ~/my_local_path
store: s3
Note
If the data at source changes, new files will be automatically synced to the bucket.
Using SkyPilot Storage CLI#
To manage buckets created by SkyPilot, the sky CLI provides two commands:
sky storage ls and sky storage delete.
sky storage lsshows buckets created by SkyPilot.
$ sky storage ls
NAME CREATED STORE COMMAND STATUS
sky-dataset 3 mins ago S3 sky launch -c demo examples/storage_demo.yaml READY
sky storage deleteallows you to delete any buckets created by SkyPilot.
$ sky storage delete sky-dataset
Deleting storage object sky-dataset...
I 04-02 19:42:24 storage.py:336] Detected existing storage object, loading Storage: sky-dataset
I 04-02 19:42:26 storage.py:683] Deleting S3 Bucket sky-dataset
Note
sky storage ls only shows storage that were created
by SkyPilot. Externally created buckets or public buckets are not listed
in sky storage ls and cannot be managed through SkyPilot.
Storage YAML reference#
file_mounts:
/remote_path:
name: str
Identifier for the storage object. Used when creating a new storage
or referencing an existing storage created by SkyPilot. Not required
when using an existing bucket created externally.
source: str
The source attribute specifies the path that must be made available
in the storage object. It can either be a local path or a list of local
paths or it can be a remote path (s3://, gs://, r2://, cos://<region_name>).
If the source is local, data is uploaded to the cloud to an appropriate
bucket (s3, gcs, r2, or ibm). If source is bucket URI,
the data is copied or mounted directly (see mode flag below).
store: str; either of 's3', 'gcs', 'r2', 'ibm'
If you wish to force sky.Storage to be backed by a specific cloud object
storage, you can specify it here. If not specified, SkyPilot chooses the
appropriate object storage based on the source path and task's cloud provider.
persistent: bool; default: True.
Whether the remote backing stores in the cloud should be deleted after
execution of the task. Set to True to avoid uploading files again
in subsequent runs (at the cost of storing your data in the cloud). If
files change between runs, new files are synced to the bucket.
mode: str; either of MOUNT or COPY; default: MOUNT
Whether attach the bucket by copying files, or mounting the remote
bucket. With MOUNT mode, files are streamed from the remote bucket
and writes are replicated to the object store (and consequently, to
other workers mounting the same Storage). With COPY mode, files are
copied at VM initialization and any writes to the mount path will
not be replicated on the bucket.